Kimi Linear是什么
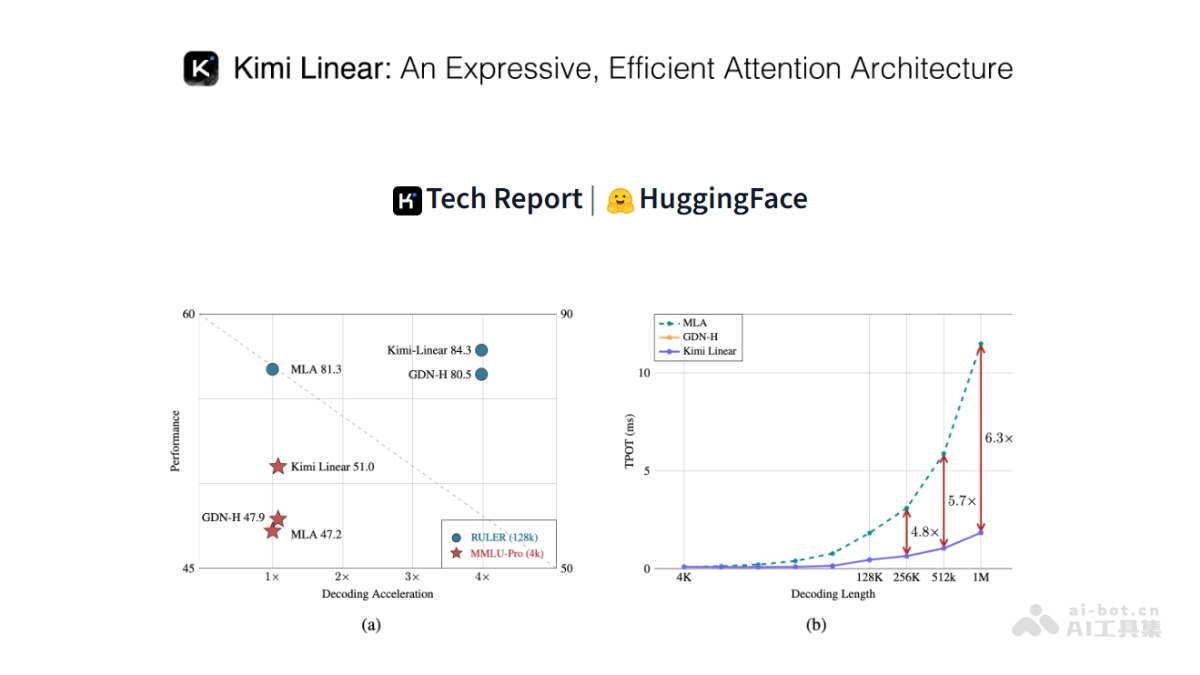
Kimi Linear 是月之暗面推出的新型混合线性注意力架构,专为提升大型语言模型(LLMs)在长序列任务中的效率和性能设计。核心组件 Kimi Delta Attention(KDA)通过精细化的通道级门控机制和高效的块处理算法,显著提升模型的表达能力和硬件效率。Kimi Linear 采用 3:1 的 KDA 与全注意力层(MLA)混合设计,大幅减少 KV 缓存的使用量(降低 75%),在处理百万级长文本时实现了 6.3 倍的解码速度提升。Kimi Linear 架构在短序列和长序列任务中均优于传统的全注意力机制,在强化学习任务中表现出色。
Kimi Linear的主要功能
- 高效处理长序列任务:Kimi Linear通过混合线性注意力架构大幅减少KV缓存使用(降低75%),在1M长文本解码中实现6.3倍吞吐量提升。
- 精确信息管理:Kimi Delta Attention(KDA)采用通道级门控机制,使模型能精确选择性地保留关键信息、遗忘无关内容,增强长序列处理能力。
- 强化推理能力:在需要复杂推理的强化学习任务中,Kimi Linear表现出色,训练准确率增长更快,测试集表现优于全注意力模型。
- 硬件友好设计:采用高效的块处理算法,充分用现代GPU的Tensor Cores,实现高矩阵乘法吞吐量,显著减少计算时间和资源消耗。
- 适应多种任务场景:Kimi Linear在短序列和长序列任务中均表现出色,适用语言理解、代码生成、数学推理等多种应用场景,具备良好泛化能力。
Kimi Linear的技术原理
- 混合线性注意力架构:Kimi Linear 基于 3:1 的混合设计,即每三个 Kimi Delta Attention(KDA)层后插入一个全注意力层(MLA)。设计结合线性注意力的高效性和全注意力的强大表达能力,同时减少 KV 缓存的使用量,提升模型的解码速度。
- Kimi Delta Attention(KDA):KDA 是 Kimi Linear 的核心模块,通过以下机制实现高效处理:
- 精细化门控机制:引入通道级门控,每个特征维度都有独立的遗忘率,类似 RoPE 的位置编码,增强模型对位置信息的感知能力。
- 硬件高效的块处理算法:采用块处理并行算法,减少计算量,提高硬件利用率。KDA 的状态转移可以视为一种特殊的对角加低秩(DPLR)矩阵,通过约束化的结构减少计算复杂度。
- 无位置编码(NoPE):Kimi Linear 的 MLA 层不使用任何显式的位置编码(如 RoPE),将位置信息的编码完全交给 KDA 层处理。设计简化了模型架构,增强了长文本任务的鲁棒性和外推能力。
- 与专家混合(MoE)结合:Kimi Linear 结合专家混合(Mixture-of-Experts, MoE)技术,通过稀疏激活模式扩展模型参数规模,进一步提升训练和推理效率。模型总参数量为 480 亿,每个前向传播仅激活 30 亿参数。
Kimi Linear的项目地址
- HuggingFace模型库:https://huggingface.co/moonshotai/Kimi-Linear-48B-A3B-Instruct
- 技术论文:https://github.com/MoonshotAI/Kimi-Linear/blob/master/tech_report.pdf
Kimi Linear的应用场景
- 长文本生成:Kimi Linear在处理百万级长文本时表现出色,解码速度提升6.3倍,适合生成长篇小说、研究报告等。
- 代码生成与理解:高效的长序列处理能力使其在代码生成和理解任务中表现出色,支持更复杂的代码逻辑和长代码片段的生成。
- 数学推理与解题:在数学任务的强化学习训练中,Kimi Linear的训练准确率增长更快,测试集表现优于全注意力模型,适合解决复杂的数学问题。
- 语言理解与问答:Kimi Linear在短序列和长序列任务中均表现出色,适用语言理解、问答系统等,支持更长的上下文理解和生成。
- 多模态任务:Kimi Linear能用于多模态任务,如图像描述生成、视频内容理解等,支持更长的文本描述和复杂的逻辑推理。
© 版权声明
文章版权归原作者所有,未经允许请勿转载。