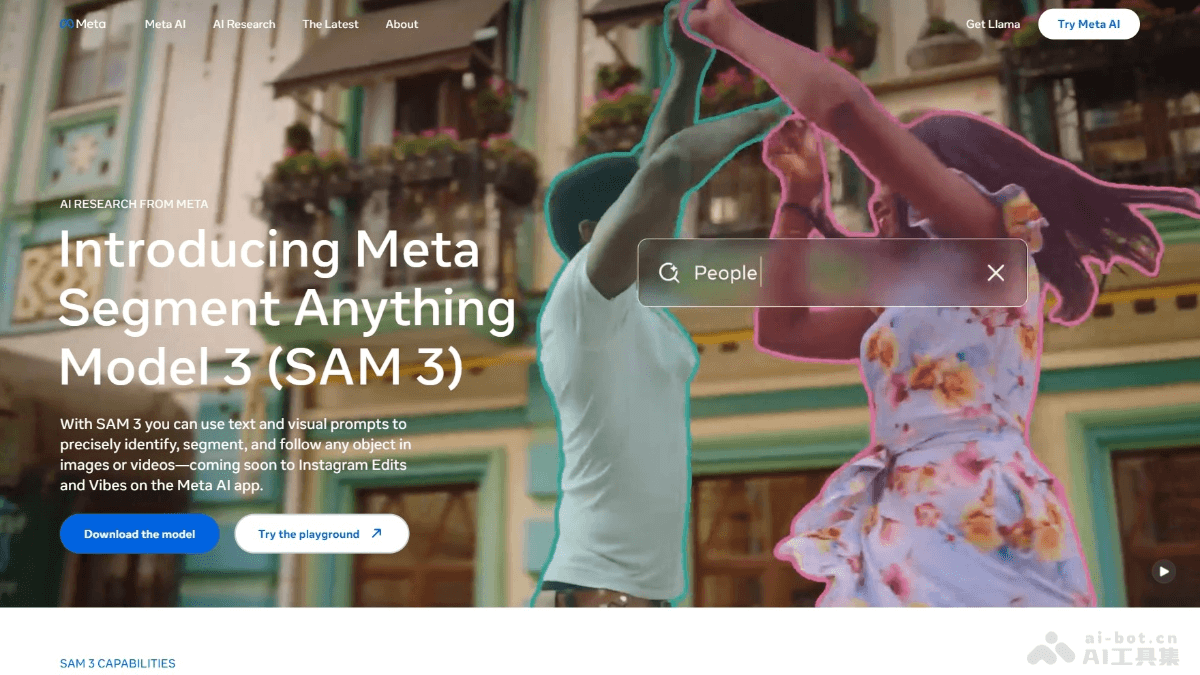
SAM 3是什么
SAM 3(Segment Anything Model 3)是 Meta AI 最新推出的先进计算机视觉模型,能通过文本、示例和视觉提示检测、分割和跟踪图像及视频中的对象。模型支持开放词汇的短语输入,具备强大的跨模态交互能力,可实时修正分割结果。SAM 3 在图像和视频分割任务中性能卓越,是现有系统的两倍,且支持零样本学习。模型扩展到 3D 重建领域,助力家居预览、创意视频编辑和科学研究等多场景应用,为计算机视觉的未来发展提供强大动力。
SAM 3的主要功能
- 多模态提示支持:SAM 3 支持通过文本、示例和视觉提示(如点击、框选)检测和分割图像及视频中的对象,适应多种用户需求。
- 图像和视频分割:SAM 3 能在图像中检测和分割所有匹配对象,支持在视频中跟踪对象,且能实时交互性修正分割结果。
- 零样本学习:SAM 3 能通过开放词汇的文本提示处理未见过的概念,无需额外训练即可分割新对象类别。
- 实时交互性:支持用户通过添加额外的提示(如点击或框选)修正模型的错误,进一步优化分割结果,提升用户体验。
- 跨领域应用:SAM 3 广泛应用在创意媒体工具(如 Instagram Edits)、家居装饰预览(如 Facebook Marketplace)和科学领域(如野生动物监测)。
SAM 3的技术原理
- 统一模型架构:SAM 3 基于统一的模型架构,同时支持图像和视频中的分割任务。模型结合强大的视觉编码器(如 Meta Perception Encoder)和文本编码器,能处理开放词汇的文本提示。模型架构包括一个图像级检测器和一个基于记忆的视频跟踪器,两者共享同一个视觉编码器。
- 多模态输入处理:
- 文本编码器:将文本提示编码为特征向量,用于指导分割任务。
- 视觉编码器:将图像或视频帧编码为特征向量,用于检测和分割对象。
- 融合编码器:将文本和视觉特征融合,生成条件化的图像特征,用于后续的分割任务。
- 存在头(Presence Head):为提高模型的分类能力,SAM 3 引入一个存在头(Presence Head),专门用在预测目标概念是否存在于图像或视频中。有助于将识别和定位任务解耦,提高模型的准确性和效率。
- 大规模数据引擎:为训练 SAM 3,Meta 构建了高效的数据引擎,结合人类标注和 AI 辅助标注,生成超过 400 万个独特概念的高质量标注数据。数据覆盖多种视觉领域和任务,确保模型具有广泛的泛化能力。
- 零样本学习:SAM 3 支持零样本学习,能处理未见过的概念。通过开放词汇的文本提示,模型用预训练的视觉和语言编码器识别和分割新的对象类别。
- 实时交互性:SAM 3 支持实时交互性,用户能通过添加额外的提示(如点击或框选)修正模型的错误,进一步优化分割结果。交互性使模型能更好地适应用户的意图。
- 视频跟踪和分割:在视频任务中,SAM 3 用基于记忆的跟踪器处理对象的时空一致性。跟踪器用检测器的输出和记忆中的历史信息,生成高质量的分割掩码,在视频帧之间传播掩码。
SAM 3的项目地址
- 项目官网:https://ai.meta.com/sam3/
- GitHub仓库:https://github.com/facebookresearch/sam3/
- 在线体验Demo:https://www.aidemos.meta.com/segment-anything
SAM 3的应用场景
- 创意媒体工具:创作者能快速为视频中的人物或物体应用特效,提升创作效率。
- 家居装饰预览:在 Facebook Marketplace 中,SAM 3 支持“房间预览”功能,用户能预览家居装饰品在自己空间中的效果,辅助购买决策。
- 科学应用:SAM 3 用在野生动物监测和海洋探索,帮助研究人员更好地理解和保护自然环境,例如通过视频分析野生动物行为。
- 3D 重建:SAM 3D 能从单张图像重建 3D 物体和人体,为物理世界场景中的 3D 重建提供新标准,助力虚拟现实和增强现实应用。
- 视频创作:SAM 3 提供 AI 视觉创作工具,支持对现有 AI 生成视频进行混剪,提升创作灵活性。
© 版权声明
文章版权归原作者所有,未经允许请勿转载。
相关文章


暂无评论...